 Sine-wave
speech cocktailsSine-wave
speech cocktails
Sine-wave
speech cocktailsSine-wave
speech cocktails
Sine-wave speech (SWS - Bailey et al, 1977; Remez et al, 1981) is a synthetic analogue of natural speech produced by a small number of time-varying sinusoids. Listeners perform well at transcribing sine-wave replicas of utterances (Remez et al, 1981; Barker & Cooke, in revision). It has been argued that SWS demonstrates the special status of speech in auditory perception (Remez et al, 1981). Of late, proponents of this hypothesis have used SWS experiments (Remez et al, 1994) to suggest that speech is beyond the reach of the 'gestalt' grouping processes which motivate the auditory scene analysis (ASA) account of sound perception (Bregman, 1990).
The present demonstration was motivated primarily by studies into the perception of simultaneous sine-wave speech utterances (Barker & Cooke, 1997). In these experiments, listeners were asked to transcribe pairs of sine-wave sentences presented simultaneously. Results were compared against (phoneme-level) transcription scores for pairs of natural utterances.
Other experiments have examined the effect of dichotic presentation (Remez et al, 1994), reduced numbers of sine-wave 'formants', further reduction of SWS to constant amplitudes or frequencies (Remez & Rubin, 1990) and the role of amplitude modulation (Carrell & Opie, 1992; Barker, 1998). The demonstration allows all of these manipulations to be explored.
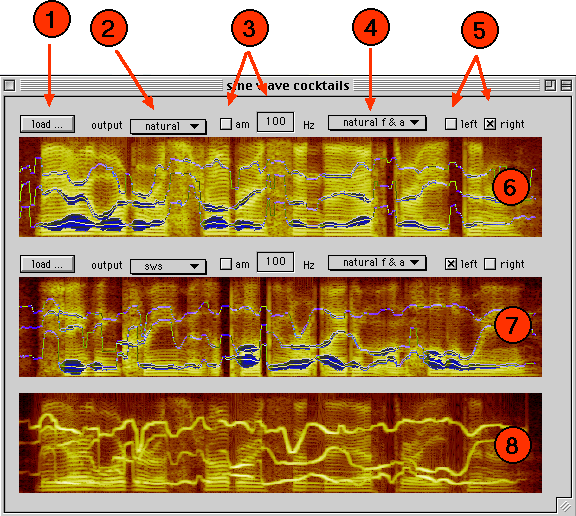
The demo is launched with the command 'sws', which brings up a window similar to the one above (without the spectrograms, initially). The window contains three display panels (6,7,8). The top two (6,7) are used to display spectrogams and SWS tracks for a pair of utterances, which are loaded via the buttons (1). The lower panel (8) displays a spectrogram of the mixture.
Once spectrograms and SWS tracks are loaded, clicking on the spectographic image results in the associated signal being played. SWS formants can be selected and unselected by clicking on the tracks. Unselected formants do not contribute to the sound output, and their absence can be noted in the mixture spectrogram.
Popup menu (2) selects which signal is used in playback. Options are 'natural', 'SWS' and 'silent'. The latter prevents the signal from contributing to the mixture.
Amplitude modulation can be added to the SWS waveform. If checkbox (3) is checked, AM at the specified rate is applied to the SWS signal. Sidebands will be visible in the mixture for all but the lowest rates of AM.
By default, SWS tracks use frequency and amplitude values extracted from the natural utterance (for details on the mainly-automatic procedure used, see Barker, 1998). Optionally, via popup menu (4), the listener can select constant amplitude or constant frequency SWS tracks.
Finally, the two signals can be presented diotically or dichotically via checkboxes (5). This option may produce odd results (e.g. one sound following another) when usd on machines which do not support stereo output.
The distribution comes with a selection of 20 SWS + natural utterances. The natural utterances come from the TIMIT CDROM.
- If you have never heard SWS before, load one of the example utterances and select SWS output from (2). Can you identify the utterance? Before listening to the natural utterance, try applying amplitude modulation (3). Does this make things easier?
- Choose a different utterance, and attempt to identify it in some of these more difficult conditions:
- with one or more formants unselected
- with constant amplitude or frequency
- with an interfering SWS utterance
- If the SWS cocktail is too lethal, try the following:
- apply AM to one of the signals
- apply different rates of AM to the two signals
- send the signals to different ears (on the same head)
- use a single SWS formant as a distractor for the other complete SWS signal.
- Listen to pairs of natural utterances. Note the ease of separation when presented dichotically, as noted long ago by Cherry (1953).
- Examine the spectrogram of a single SWS source (you will have to turn one of the two off at this point). What cues present in the natural speech spectrogram are missing?
- Examine the spectrogram of the mix. Are there any cues which might be used to separate the source without speech knowledge? [See Barker (1998) for some suggestions].
- Bailey et al (1977). TR SR-51/52, Haskins Labs.
- Barker & Cooke (1999). Speech Communication.
- Barker (1998). PhD Thesis, University of Sheffield.
- Bregman (1990). Auditory Scene Analysis. MIT Press.
- Carrell & Opie (1992). Perc. & Psych., 52, 437-445.
- Cherry (1953). JASA, 25, 975-979.
- Remez et al (1981). Science, 212, 947-950.
- Remez & Rubin (1990). Perc. & Psych., 48(4), 313-325.
- Remez et al (1994). Psych. Review., 101(1), 129-156.
Produced by: Martin Cooke. SWS data provided by Jon Barker.
Release date: June 22 1998
Permissions: This demonstration may be used and modified freely by anyone. It may be distributed in unmodified form.